论文阅读 - Towards Robust Semantic Role Labeling
ACL 2007
为暑研工作阅读的第一篇论文。暑研工作的三个基石之一:SRL(Semantic Role Labeling)。现在大部分 SRL system 都基于一个数据集完成的训练。作者认为这样会造成过拟合现象。这篇文章提供了一种在特定数据集上标注后迁移到另一个数据集的方法。本篇文章基于 PropBank(很快我也需要完成这篇文章的阅读了。)这篇文章认为语法上的 parser 和 argument 判断可以很容易的迁移,然而 argument classification 不是。
Introduction
SRL 是一种用来表征语法结构的方法。党表征一个句子时,一个好的语法标注器应当能够对句子中的每一个谓词,正确地辨别并标注出其语法 label。在近期的工作中,这个工作是通过监督机器学习完成的。尽管这些工作在数据集上都达到了很高的准确率,但是他们极大地与其训练的数据集相关。这篇文章的焦点就是讨论这样的现象。
实验基于 PropBank corpus(这是一个 WSJ 的标注数据集)完成。
语义标注(Semantic Role Labeling)
成分分析(constituent parsing)
成分解析树将一个句子划分为一棵成分树,树上的非叶子节点是划分成的短语,叶子节点是句子中的单词。
在 NLP 中,分析方法分为:
- 词法分析 lexical analysis
- 句法分析 syntactic parsing
- 语义分析 semantic parsing
其中语义分析是指将自然语言句子转化为反映这个句子语义的形式化表达。例如:
我吃了一块肉
一块肉被我吃了
在语义上都表示为吃(我,肉)的意思,但句子结构却有不同。句子的语义分析是对句子处理技术更高一级的要求,在信息检索、信息抽取、自动文摘等应用广泛。
SRL: Semantic Role Labeling (SRL) is defined as the task to recognize arguments for a given predicate and assign semantic role labels to them.
SRL 是浅层语义分析技术,以句子为单位处理为“谓词+论元”的结构。
语义标注和语料库
这篇文章通过复现 PropBank corpus 中的语义标注方法完成实验。PropBank 是一个包含 300k 单词的语料库,其中对于除了系词(corpula)外的所有动词都标注了谓词 argument 关系。PropBank 使用了 Arg0~Arg5 作为谓词 labels。
- ARG0: Agent, operator
- ARG1: Things operated
- ARG2: EXplicit patient
- ARG3: Explicit argument
- ARG4: Explicit instrument
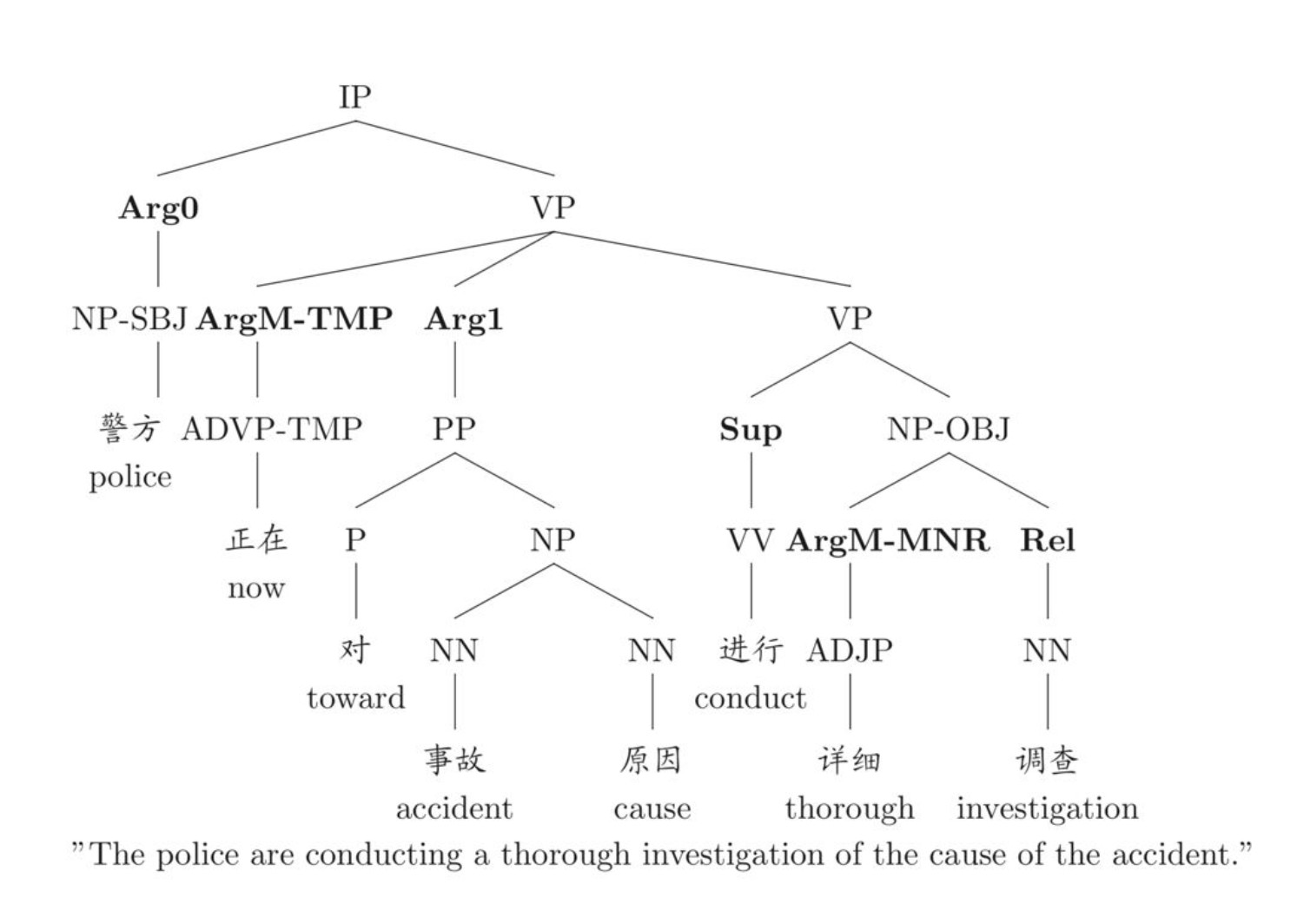 Semantic Tree
Semantic Tree
除了这些基本的标志外,还存在 adjuntive argument(ArgMs),以及 ArgM-Loc,Arm=gM-TMP 等等。对于下面的例子,使用 operate 作为候选词获得的标注:
It operates stores mostly in Iowa and Nebraska.
[${ARG0}$It] [${谓词}$operates] [${ARG1}$ stores][${ARGM−LOC}$ mostly in Iowa and Nebraska].
PropBank 假定对于一个谓词的语义单元只存在一个或多个 nodes。尽管对于大部分的 arguments 树只有一个 node,但多个 node 的情况也是存在的。
任务描述
在 ASSERT 中,SRL 是通过对于一个 syntactic parse 的组分分配一个 role label 实现的。基本上可以被分到三个步骤:
- Argument identification:对于一个给定的谓词,识别句子成分。对于 parse tree 中的任何一个 node,可以被分类为具有语义表示(Not Null Node)或者不具备任何语义内涵。
- Argument classification:假定已知一个谓词的组成已知,这个步骤将 argument label 赋给这些组成。
- Argument identification and classfication:上述两个任务的组合。
ASSERT(Automatic Statistical Semantic Role Tagger)
模型架构
ASSERT 对每一个谓词生成一组 SRL(不同于 PropBank,系词是考虑在内的)。模型基本的输入是一个句子以及成分分析树。对于每一个分析树中的成分,ASSERT 提取出一组特征,并使用分类器对这个成分指定标签。该模型使用 SVM 方法及“one vs all”构建 n 个分类器,每一个分类器的结果被综合对标签进行判断。
上述使用的方法有一个缺陷:每一个 argument 的分类是独立的,而没有考虑其他被赋给相同标签的 argument。这样会忽略部分信息。
特征
使用的特征如下:
- 谓词:确定 arguments 所使用的这一个谓词,同时该谓词的形式及语法信息同样作为特征输入。
- 路径:从分析树到当前分类谓词的路径。
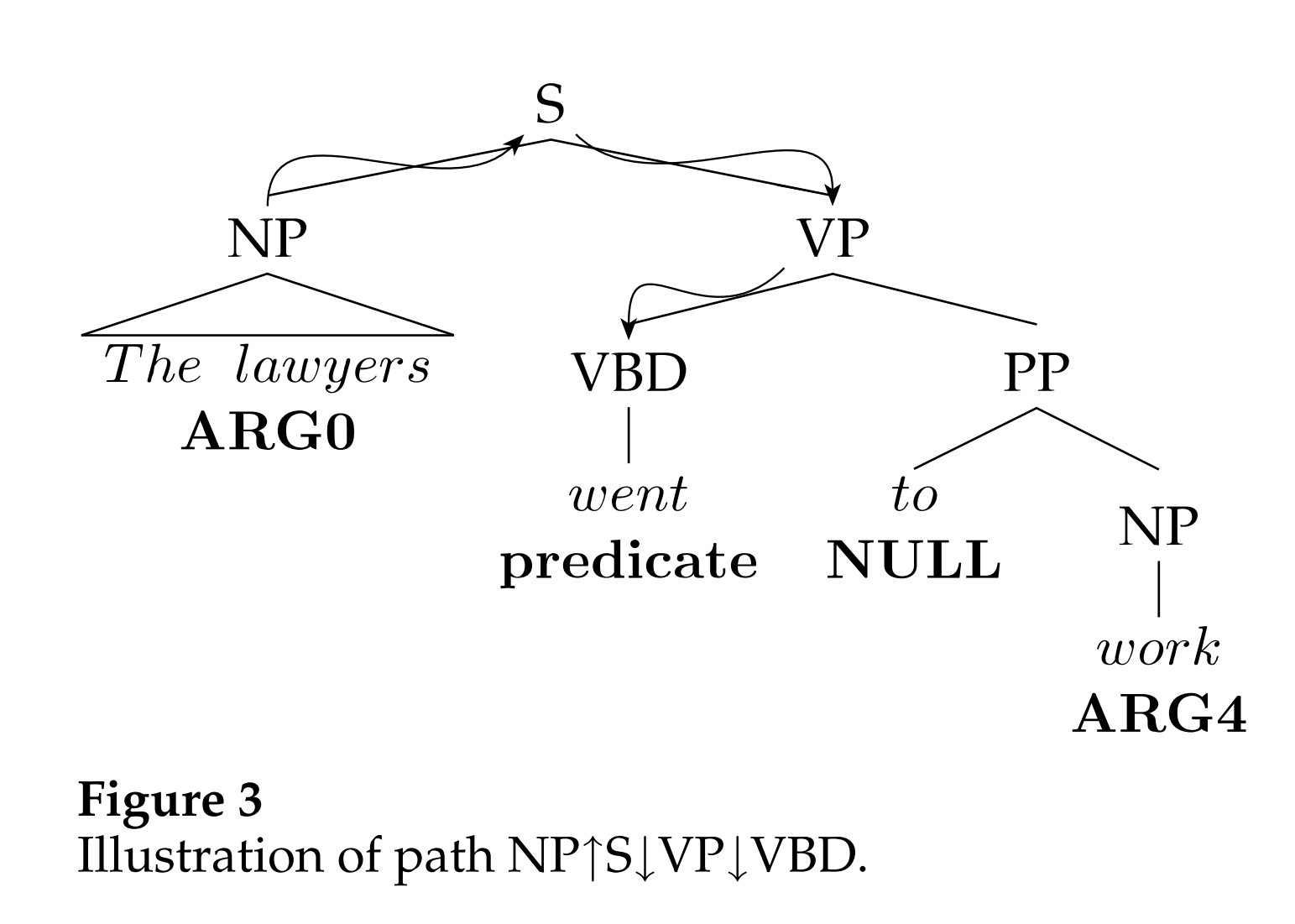
- 短语类型:比如 PP,NP 等等成分。
- 位置:这个成分出现在谓词前还是谓词后
- 状态:这个谓词是主动的还是被动的。
- 子类?:这个谓词的子节点,例如在上图中:
VP -> VBD - PP - NP。 - 谓词 cluster:直观是,对于相似的语法结构的动词应该有相似的对象。例如“eat&devour”。动词被分为 64 类,然后通过这个分类作为特征。
- Head word:这个成分的 head。
- Head word Pos:这个 head word 的 pos。
- 成分中的 named entity。
- …… 太多了,不一一列举了。
在实验过程中,对于 Identification Task 和 Classification Task 的有效特征是不同的。对于 IT,有效的特征是 Path 和 Partial Path,而谓词并不是非常重要。而对于分类,更重要的是 Head word,First/Last word 这些词。
简单的结论是,结构性的特征(如 Path)对于 IT 有积极作用,而更 lexical 的词或语义上的特征则对于分类更加重要。
鲁棒性分析
基本上目前的研究都将注意力放在了带有某种相同风格的文本上,对于这些文本集表现得提高可能更多意味着对于某类文本的辨识力/拟合,然而 SRL 等工具应当是普适意味的……为了表现这些模型确实不具有很强的迁移能力,引入下列的数据集。
The Brown Corpus
BC 是美式英语标准语料库,包含 1 百万英文文本,收录 2000 多词越 500 个样本。这个数据集用做语言对照分析。
跨风格测试
这一个测试表现模型在一个数据集上训练以后迁移到另一个数据集上是训练得到的结果差异。其选择在 WSJ 模型上先完成训练,然后迁移到 BS 上进行对比。我们掠过结果分析部分。
结论
获得了在 PropBank 上的 SRL SOTA,并使用这个结果在 Brown 语料库上进行检验。事实证明,在 Brown 上的模型表现大幅度下降,作者认为其中 Identification 步骤对模型能力下降影响不大,分类部分是模型能力下降的主要原因。